Qu’est-ce qu’une classe d’adresses IP ? Importance des VPN et de la cybersécurité



Tout appareil qui se connecte à Internet a besoin d’une adresse qui l’identifie sur le réseau. Des classes d’adresses IP (Internet Protocol) ont été créées pour organiser ces adresses et décider du nombre d’adresses pouvant être utilisées au sein de chaque réseau. Ce système a ensuite été remplacé par un modèle sans classe, qui alloue les blocs d’adresses de manière plus efficace.
Néanmoins, la logique qui sous-tend la structure des classes IP détermine toujours la manière dont les réseaux modernes sont organisés. Il influence la façon dont les réseaux privés virtuels (VPN) attribuent les adresses privées, la façon dont le trafic est séparé au sein des organisations et la façon dont la communication reste sécurisée entre les systèmes connectés.
Cet article explique ce que sont les classes d’adresses IP, comment elles fonctionnent et pourquoi le principe qui les sous-tend reste d’actualité pour les VPN, la protection de la confidentialité et la conception des réseaux modernes.
Qu’est-ce qu’une adresse IP ?
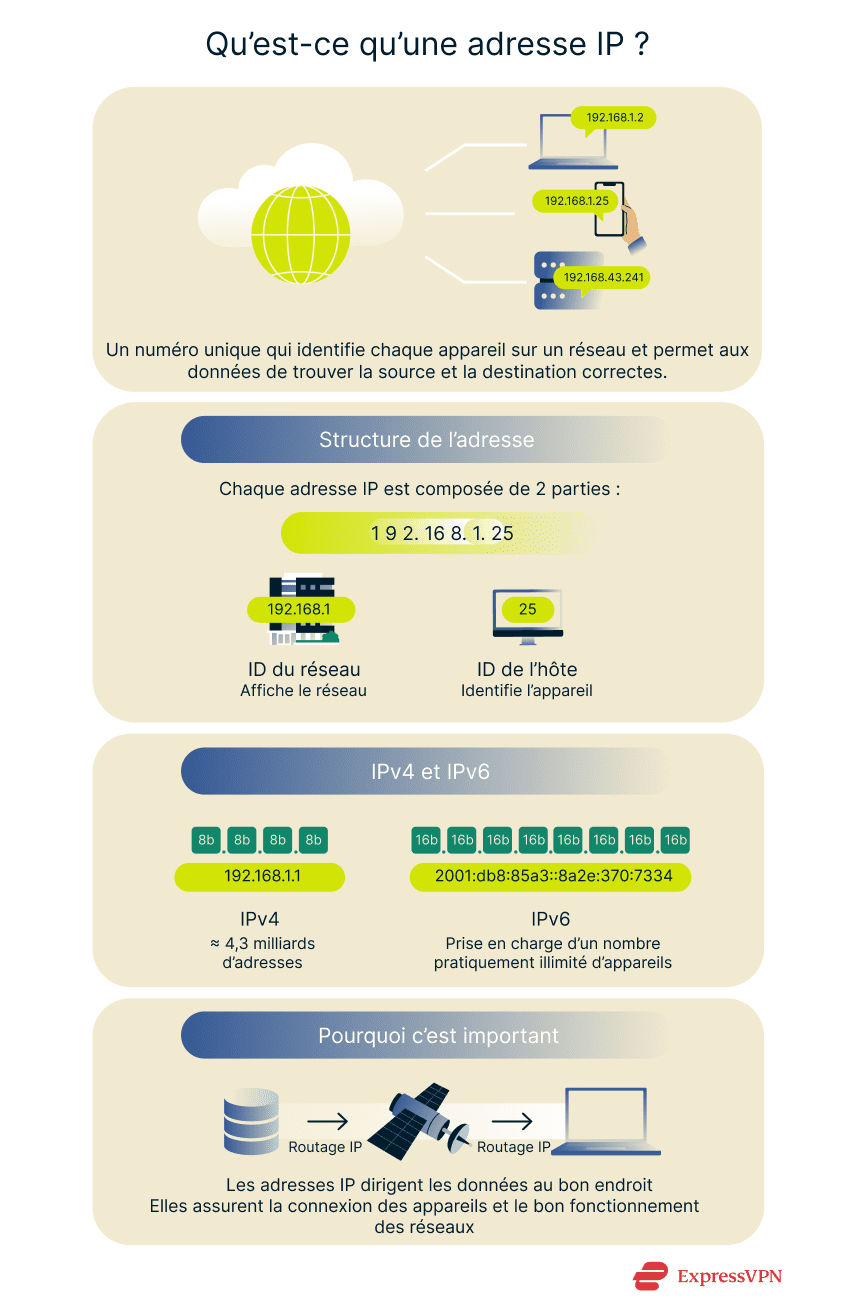 Une adresse IP est un numéro unique attribué à tout appareil qui se connecte à Internet ou à un réseau privé utilisant le protocole Internet. Elle identifie la source et la destination des paquets de données, ce qui permet aux systèmes d’échanger des informations sur un réseau ou sur Internet.
Une adresse IP est un numéro unique attribué à tout appareil qui se connecte à Internet ou à un réseau privé utilisant le protocole Internet. Elle identifie la source et la destination des paquets de données, ce qui permet aux systèmes d’échanger des informations sur un réseau ou sur Internet.
Il existe deux versions du protocole Internet actuellement utilisées : IPv4 et IPv6. Les adresses IPv4 sont construites sur le système binaire et contiennent 32 bits au total. Elles sont divisées en quatre sections appelées octets, chacune contenant 8 bits. Sous une forme lisible par l’homme, ces octets sont écrits sous forme de nombres décimaux séparés par des points, un format connu sous le nom de notation décimale à point.
Chaque octet peut avoir une valeur comprise entre 0 et 255, car 8 bits peuvent représenter 256 combinaisons différentes (2⁸ = 256). Par exemple, une adresse IPv4 ressemble à ceci :
192.168.43.241
En coulisses, les ordinateurs traitent ces nombres sous forme binaire. La même adresse ci-dessus apparaîtrait comme suit :
- 192 → 11000000
- 168 → 10101000
- 43 → 00101011
- 241 → 11110001
Ainsi, en binaire, 192.168.43.241 s’écrit 11000000.10101000.00101011.11110001.
Ce modèle fournit environ 4,3 milliards d’adresses uniques. Les premières implémentations les regroupaient en catégories fixes appelées classes afin de simplifier l’organisation et le routage des réseaux.
Chaque adresse IP comporte deux sections : l’une spécifie le réseau et l’autre identifie l’appareil (hôte) qui s’y trouve. Cette structure permet aux données de circuler vers la bonne destination et empêche les adresses en double de provoquer des erreurs de routage à l’intérieur des réseaux ou entre eux.
IPv6 étend la taille de l’adresse IP à 128 bits et l’écrit en hexadécimal séparé par des deux points : par exemple, 2001:db8:85a3::8a2e:370:7334. L’augmentation de la taille crée un nombre immense d’adresses possibles (environ 340 milliards), ce qui favorise l’expansion continue d’Internet.
Les deux versions jouent le même rôle : elles attribuent à chaque appareil une identité unique afin que les informations puissent être transmises avec précision entre les réseaux. Bien que la réserve mondiale d’adresses IPv4 soit épuisée, l’IPv4 reste la norme principale pour la plupart des communications Internet et réseau actuelles. L’adoption de l’IPv6 progresse, mais les deux protocoles continuent de coexister au fur et à mesure que la transition progresse.
Consultez également : Différence entre les adresses statiques et dynamiques
Les 5 classes d’adresses IP
Lorsque l’IPv4 a été introduit pour la première fois, l’ensemble de l’espace d’adressage a été divisé en cinq classes d’adresses IPv4 : A, B, C, D et E. Chaque classe spécifie le nombre de réseaux qui peuvent exister et le nombre d’hôtes individuels que chaque réseau peut contenir. Ce système a donné aux premiers ingénieurs réseaux un moyen prévisible d’attribuer des adresses et de connecter des réseaux d’échelles différentes sans chevauchement. Cette structure est connue sous le nom d’adressage IP par classe.
Dans le système basé sur les classes, la structure IPv4 de 32 bits était divisée en parties fixes pour le réseau et l’hôte. Les réseaux de classe A ont réservé les 8 premiers bits à la partie réseau, ceux de classe B en ont utilisé 16 et ceux de classe C, 24. Ces valeurs sont généralement exprimées sous forme de préfixe (/8, /16 ou /24) ou sous forme de masque de sous-réseau par défaut, tel que 255.0.0.0 pour la classe A.
Cette conception a rendu l’attribution des adresses prévisible dans les premiers jours d’Internet : les grandes organisations recevaient des blocs de classe A, les réseaux de taille moyenne recevaient des blocs de classe B et les plus petits recevaient des blocs de classe C. Les classes D et E étaient réservées à des utilisations spéciales : le multicasting, ou multidiffusion, et les utilisations expérimentales.
Bien que l’adressage par classe ne soit plus utilisé pour l’attribution de nouveaux blocs IP, il permet toujours d’expliquer comment les réseaux IPv4 sont organisés aujourd’hui. Les systèmes modernes s’appuient sur le routage interdomaine sans classe (CIDR) pour l’attribution et le routage, mais les plages de classes d’origine continuent d’influencer les espaces d’adresses privés. Request for Comments (RFC) 1918, qui définit les plages IP privées, s’inspire des anciens blocs de classe A, B et C.
| Classe | Première adresse | Dernière adresse | Masque par défaut | Utilisation type |
| A | 0.0.0.0 | 126.255.255.255 | 255.0.0.0 (/8) | Très grands réseaux (historiques) |
| 128.0.0.0 | 191.255.255.255 | 255.255.0.0 (/16) | Réseaux moyens (historiques) | |
| C | 192.0.0.0 | 223.255.255.255 | 255.255.255.0 (/24) | Petits réseaux (historiques) |
| D | 224.0.0.0 | 239.255.255.255 | n/a | Multicast (multidiffusion) |
| E | 240.0.0.0 | 255.255.255.254 | n/a | Expérimentations |
Classe A
Un réseau d’adresses IP de classe A a été créé pour les très grands réseaux tels que les administrations, les grands fournisseurs de télécommunications et les premiers opérateurs de dorsale Internet. Il s’étend de 1.0.0.0 à 126.255.255.255 et utilise un préfixe /8, ce qui signifie que les 8 premiers bits identifient le réseau comme expliqué ci-dessus. Le masque par défaut est 255.0.0.0.
Un seul réseau de classe A pouvait contenir plus de 16 millions d’adresses uniques, ce qui convenait aux grands systèmes gouvernementaux, universitaires et de télécommunications qui dominaient Internet à ses débuts. Aujourd’hui, ces blocs massifs ne sont plus conservés d’un seul tenant. Ils sont divisés en sous-réseaux plus petits afin de rendre le routage plus efficace et de simplifier la gestion des adresses.
Classe B
Les réseaux d’adresses IP de classe B étaient destinés aux organisations de taille moyenne telles que les universités, les grandes entreprises et les fournisseurs d’accès Internet régionaux. Leur plage d’adresses s’étend de 128.0.0.0 à 191.255.255.255, en utilisant un préfixe /16 et le masque de sous-réseau par défaut 255.255.0.0.
Chaque bloc de classe B fournit environ 65 000 adresses utilisables, ce qui est suffisant pour des systèmes internes complexes tout en restant pratique à administrer. Cet équilibre a fait de la classe B l’une des catégories les plus largement émises dans les premiers jours d’Internet.
Classe C
Les réseaux d’adresses IP de classe C ont été créés pour les petites structures telles que les bureaux, les réseaux privés et les agences. Leur plage s’étend de 192.0.0.0 à 223.255.255.255 et utilise un préfixe /24 avec un masque par défaut de 255.255.255.0.
Chaque bloc de classe C peut prendre en charge jusqu’à 254 appareils. Ces allocations plus petites étaient efficaces pour les environnements locaux et restent la norme pour les réseaux privés et les réseaux de petites entreprises.
Classe D
Les adresses IP de classe D sont réservées au multicast, qui permet à un expéditeur de diffuser le même flux de données à de nombreux destinataires. En revanche, l’unicast transmet les données d’un émetteur à un seul récepteur.
Cette plage d’adresses s’étend de 224.0.0.0 à 239.255.255.255. Les appareils qui souhaitent participer à une session de multicast rejoignent un groupe de multidiffusion et reçoivent les données que la source leur transmet. Le multicast est utilisé pour le streaming, les conférences et d’autres applications en temps réel qui doivent envoyer des informations identiques à plusieurs terminaux de manière efficace.
Classe E
Les adresses IP de classe E couvrent la plage 240.0.0.0 à 255.255.255.254 et ont été réservées à la recherche et à l’expérimentation. Ces adresses ne sont pas acheminées sur Internet public et la plupart des systèmes actuels les ignorent tout simplement pour les communications normales.
Bien que plusieurs projets de résolution aient proposé de réaffecter la classe E (240.0.0.0/4) afin de pallier l'épuisement des adresses IPv4, l’Internet Assigned Numbers Authority (IANA), qui gère l’attribution mondiale des adresses IP, continue de réserver la classe E à des usages non standard ou expérimentaux.
Plages d’adresses IP spéciales
Toutes les adresses IPv4 ne sont pas destinées à un usage public. Certains sont réservés à la communication interne, aux tests ou à la configuration automatique. Ces plages spéciales permettent aux appareils de fonctionner et de communiquer de manière fiable même sans accès direct à Internet au sens large.
Adresses IP réservées
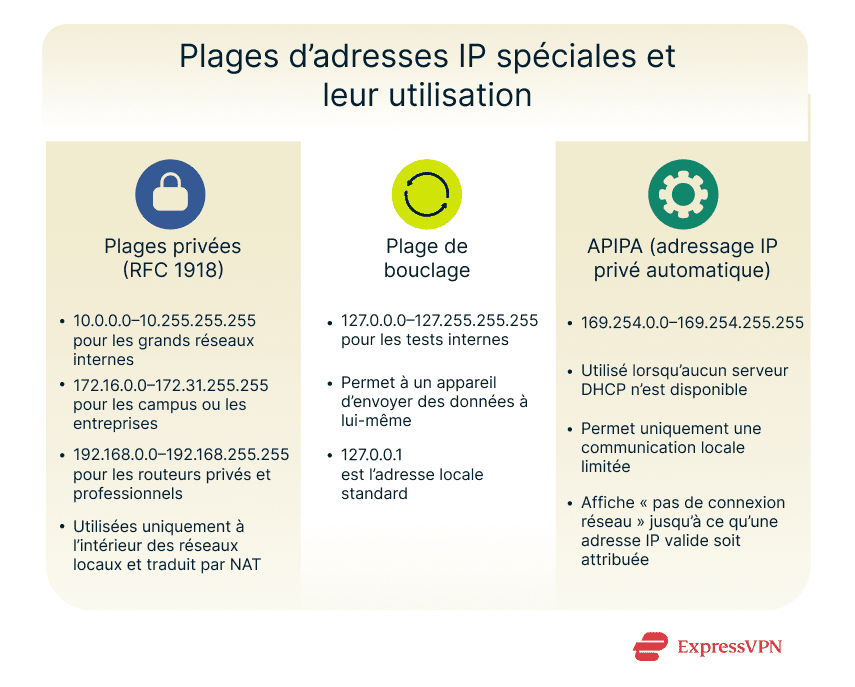
Certains blocs d’adresses sont réservés aux réseaux privés et ne peuvent pas être utilisés sur l’Internet public. Ils appartiennent aux classes traditionnelles A, B et C et sont définis dans la RFC 1918.
- 10.0.0.0 à 10.255.255.255 (plage de classe A) : Ce bloc est souvent utilisé dans les grandes organisations ou les centres de données où des milliers d’appareils partagent le même réseau interne. En raison de sa taille, il permet une subdivision en sous-réseau flexible pour plusieurs départements ou services.
- 172.16.0.0 à 172.31.255.255 (plage de classe B) : Cette plage convient aux réseaux de taille moyenne, tels que les campus universitaires ou les grandes entreprises. Elle offre un bon équilibre entre capacité et facilité de gestion, et prend en charge des dizaines de milliers d’appareils connectés.
- 192.168.0.0 à 192.168.255.255 (plage de classe C) : Cette plage est largement utilisée dans les routeurs domestiques et les petits routeurs de bureau. Des adresses telles que 192.168.0.1 ou 192.168.1.1 sont des valeurs par défaut courantes pour les passerelles locales qui connectent des appareils privés à Internet.
Les appareils qui utilisent des IP privées ne peuvent pas être joints directement depuis Internet. Lorsqu’ils doivent accéder à des sites externes, les routeurs traduisent ces adresses privées en adresses publiques à l’aide d’un processus appelé traduction d’adresses de réseau (NAT).
Cela permet à de nombreux appareils de partager une seule adresse IP publique, ce qui permet de conserver l’espace d’adressage tout en cachant les adresses internes.
Adresses loopback
Le bloc 127.0.0.0-127.255.255.255 est réservé à ce que l’on appelle l’interface loopback : une connexion réseau virtuelle qu’un appareil utilise pour s’envoyer des données à lui-même.
L’adresse la plus connue de cette plage est 127.0.0.1, qui renvoie simplement au même appareil. Toutes les données qui lui sont envoyées restent à l’intérieur du système au lieu d’être envoyées sur un réseau.
Cette configuration offre aux développeurs et aux administrateurs un moyen sûr de tester les logiciels, les services et les paramètres du réseau sans impliquer de connexions externes. Par exemple, un serveur web fonctionnant sur votre propre ordinateur peut être ouvert dans un navigateur en visitant 127.0.0.1.
Automatic Private IP Addressing (APIPA, pour adressage IP privé automatique)
Si un appareil ne peut pas obtenir d’adresse IP d’un serveur Dynamic Host Configuration Protocol (DHCP) (un système de réseau qui les attribue normalement), il en génère une pour lui-même dans la plage 169.254.0.0 à 169.254.255.255. C’est ce qu’on appelle l’adressage IP privé automatique (APIPA).
APIPA permet aux appareils d’un même sous-réseau local de communiquer lorsqu’aucun routeur ou serveur DHCP n’est disponible : par exemple, deux ordinateurs connectés au même commutateur ou au même point d’accès sans fil. Ces adresses sont limitées au trafic local et ne peuvent pas atteindre Internet.
Lorsqu’un serveur DHCP redevient disponible, l’appareil libère son adresse APIPA et utilise celle attribuée par le réseau. Si l’appareil ne parvient pas à obtenir une nouvelle adresse IP après que le serveur DHCP est devenu disponible, il peut rester sur son adresse APIPA auto-attribuée et afficher une erreur « no network connection » (pas de connexion réseau) ou « no Internet access » (pas d’accès à Internet).
Classes d’adresses IP et sécurité dans les VPN
La façon dont les adresses IP sont organisées est toujours importante pour un VPN. C’est ce qui détermine le regroupement des appareils, la circulation du trafic au sein du réseau et la séparation des adresses privées par rapport à l’Internet public.
Pourquoi les VPN reposent-ils sur des adresses IP privées ?
Lorsqu’un appareil se connecte à un VPN, il se voit attribuer une adresse IP privée qui n’existe qu’au sein de ce réseau. L’adresse est généralement tirée des plages RFC 1918, qui ne sont pas acheminées sur l’Internet public.
Une fois attribué, le VPN établit un tunnel chiffré entre votre appareil et son serveur. Tout le trafic passe par ce tunnel, ce qui permet de dissimuler votre véritable adresse IP et les détails de votre réseau interne lorsque vous traversez des réseaux publics.
Le serveur, quant à lui, communique avec les sites web externes par le biais de sa propre adresse IP publique. Cette séparation entre l’adressage privé et l’adressage public maintient les appareils des utilisateurs à l’écart de l’Internet ouvert et dissimule la manière dont le réseau interne est structuré.
Dans de nombreuses configurations de VPN d’entreprise, la segmentation est intégrée. Les administrateurs peuvent attribuer des sous-réseaux distincts à différents utilisateurs, services ou bureaux distants, puis appliquer des règles distinctes de pare-feu, de système de noms de domaine (DNS) ou de liste blanche d’IP à chacun d’entre eux. Cela permet de limiter ce que chaque groupe peut voir et de confiner les données aux groupes qui doivent y avoir accès.
Classes d’adresses IP et confidentialité en ligne
Les sites web et les services en ligne peuvent voir l’adresse IP publique que votre connexion utilise. À partir de cette adresse, ils peuvent souvent déterminer votre emplacement général et le fournisseur qui s’occupe de votre trafic. Un VPN remplace cette IP visible par l’adresse de son propre serveur, de sorte que le site voit l’adresse IP du serveur VPN au lieu de la vôtre.
Les plages d’adresses privées, issues de l’ancien modèle des classes IP, jouent également un rôle dans la protection de la confidentialité. Les appareils qui les utilisent se trouvent derrière des routeurs ou des passerelles VPN qui exécutent la NAT. De ce fait, les systèmes extérieurs ne voient pas la structure interne : chaque demande semble provenir du terminal public du VPN.
Les VPN actuels ajoutent une protection supplémentaire en faisant tourner les adresses IP de leurs serveurs, en empêchant les fuites de DNS ou d’IPv6 et en bloquant les itinéraires de secours susceptibles de révéler l’emplacement réel de l’utilisateur. En effet, le VPN se superpose à l’Internet public comme une couche de réseau privé qui sécurise l’identité et les données pendant que le trafic y transite. Ces protections au niveau du réseau s’alignent sur les normes de sécurité réseau plus larges utilisées dans les organisations modernes.
La subdivision en sous-réseau et sa relation avec les classes IP
La structure basée sur les classes rendait l’attribution des adresses prévisible, mais qui manque de souplesse. Par exemple, si vous êtes une organisation qui a besoin de 500 adresses IP, vous ne pouvez pas utiliser une adresse de classe C, qui ne vous donnerait que 254 adresses. Vous devrez donc opter pour une IP de classe B avec 65 000 adresses, ce qui vous donnera 64 500 adresses que vous n’utiliserez jamais.
La subdivision en sous-réseau a été introduit pour assouplir les limites rigides des classes. Au lieu de traiter l’ensemble d’une classe A ou B comme un seul bloc, la subdivision en sous-réseau permet aux administrateurs de la diviser en segments logiques plus petits, chacun ayant sa propre plage d’adresses IP et ses propres règles de routage interne. Ces réseaux plus petits, ou sous-réseaux, peuvent ensuite être acheminés et sécurisés de manière indépendante, ce qui améliore à la fois l’efficacité et le contrôle.
Qu’est-ce que la subdivision en sous-réseaux, ou subnetting ?
Le subnetting divise un réseau IP unique en parties plus petites et structurées. Chaque sous-réseau fonctionne indépendamment à l’intérieur du réseau principal et se connecte à d’autres sous-réseaux par l’intermédiaire d’un routeur ou d’une passerelle.
Il s’agit de prendre des bits de la partie hôte d’une adresse IP et de les utiliser pour étendre la partie réseau. La subdivision définit le nombre de sous-réseaux existants et le nombre d’appareils que chacun d’eux peut contenir.
Supposons qu’une entreprise dispose du bloc 172.16.0.0/16. Elle peut le diviser en plusieurs réseaux /24, chacun pouvant accueillir 254 appareils. L’espace d’adressage n’augmente pas (et il ne diminue que de façon négligeable avec l’introduction d’une nouvelle adresse de diffusion et d’une nouvelle adresse réseau pour chaque réseau). Ce découpage simplifie le routage et facilite l’application des politiques de sécurité.
Le sous-réseau comparé au masque de sous-réseau
Les termes « sous-réseau » et « masque de sous-réseau » sont liés, mais ils ont des objectifs différents :
- Masque de sous-réseau : Le masque de sous-réseau est le mécanisme qui permet la création de sous-réseaux. Il s’agit d’un modèle de 32 bits qui indique aux appareils quelle partie de l’adresse IP correspond au réseau et quelle partie correspond à l’hôte.
- Les bits réglés sur 1 marquent la partie réseau.
- Les bits mis à 0 marquent la partie hôte.
Lorsqu’un appareil compare sa propre adresse IP avec un masque de sous-réseau, il peut déterminer si une autre adresse fait partie du même sous-réseau ou doit être acheminée en dehors de celui-ci.
- Sous-réseau : Un sous-réseau est le résultat d’un masque de sous-réseau. Il s’agit d’un petit segment indépendant d’un réseau IP plus vaste. Chaque sous-réseau a sa propre plage d’adresses, son adresse de diffusion et souvent ses propres règles de routage ou d’accès. Il définit où un réseau logique se termine et où un autre commence.
Le même format fonctionne pour des réseaux de tailles différentes. Un masque /24 (255.255.255.0) fournit 256 adresses au total, dont 254 utilisables par les hôtes après en avoir réservé une pour le réseau et une pour la diffusion. Un masque /25 (255.255.255.128) divise cette plage en deux sous-réseaux de 128 adresses chacun, ce qui permet d’utiliser 126 hôtes par sous-réseau.
Cette capacité à redéfinir les frontières de manière dynamique est ce qui rend la subdivision de sous-réseau si puissant.
Objectif et avantages du subnetting
Le subnetting offre des avantages en termes d’efficacité opérationnelle et de sécurité, notamment :

- Utilisation efficace des adresses : La taille des sous-réseaux peut correspondre au nombre d’appareils sur chaque segment, ce qui permet d’éviter que de grandes parties de l’espace d’adressage ne restent inutilisées.
- Performance : Le trafic local reste à l’intérieur de son propre sous-réseau, ce qui réduit le bruit de diffusion et allège le routage.
- Gestion : La division d’un réseau en fonction de son objectif (par exemple, séparer le personnel de bureau, le Wi-Fi invité et les serveurs) facilite l’organisation et la surveillance.
- Sécurité : Le trafic entre les sous-réseaux peut être contrôlé. Les pare-feu ou les passerelles VPN peuvent empêcher les menaces de se propager au-delà de leur point de départ.
- Dépannage : Lorsqu’un problème survient, il n’affecte que ce sous-réseau. Le reste du réseau continue de fonctionner.
- Évolutivité : D’autres sous-réseaux peuvent être ajoutés ultérieurement ou fusionnés lorsque le réseau s’agrandit.
Exemples pratiques de subnetting
- Segmentation dans le cadre d’une entreprise : Une entreprise utilisant un bloc 172.16.0.0/16 peut le diviser en plusieurs sous-réseaux /24, tels que 172.16.1.0/24, 172.16.2.0/24, et ainsi de suite, en attribuant à chaque département sa propre plage et sa propre politique de pare-feu. Un fournisseur d’accès à Internet (FAI) disposant d’un réseau 172.16.0.0/16 peut allouer des plages 172.16.1.0/24, 172.16.2.0/24 et d’autres plages similaires à ses clients.
- Réseaux privés et de petites entreprises : La plupart des routeurs grand public utilisent 192.168.1.0/24 par défaut, prenant en charge jusqu’à 254 appareils connectés dans la plage 192.168.1.2-192.168.1.253. Un masque /25 (255.255.255.128) peut être utilisé pour diviser cet espace en deux sous-réseaux plus petits de 126 hôtes chacun : un pour les appareils de travail et un autre pour les connexions d’invités. Les utilisateurs qui ont besoin d’adresses locales fixes pour les imprimantes ou les serveurs peuvent configurer une adresse IP statique par le biais des paramètres du routeur.
- Segmentation VPN : Les VPN d’entreprise et open-source peuvent attribuer des sous-réseaux uniques à différents groupes, sites ou utilisateurs. Les administrateurs peuvent ainsi appliquer des règles de pare-feu distinctes pour chaque sous-réseau, ce qui permet d’isoler le trafic et de simplifier le routage à l’intérieur du tunnel VPN.
Les classes d’adresses IP sont-elles encore pertinentes aujourd’hui ?
Le système basé sur les classes a permis d’organiser les premiers réseaux, mais il n’est plus utilisé pour l’attribution des adresses. Il ne permet que de comprendre la structure de l’IPv4, et non le routage ou la distribution modernes.
Inconvénients du système de classes
L’adressage par classe était facile à mettre en œuvre, mais il gaspillait beaucoup d’espace. Les plages fixes fonctionnaient lorsqu’Internet était petit, mais ont rapidement rencontré des limites au fur et à mesure que les réseaux se développaient.
De grands blocs d’adresses ont été attribués aux premiers réseaux gouvernementaux, universitaires et d’entreprise, tandis que les organisations plus petites ont dû se contenter de la plage limitée de la classe C. Chaque réseau de classe C ne pouvant contenir qu’environ 250 hôtes, de nombreux petits réseaux se sont rapidement retrouvés à court d’adresses disponibles.
Les tables de routage (les listes qui indiquent aux routeurs où envoyer le trafic) ont également été surchargées, car chaque bloc de réseau devait être enregistré séparément, même si une grande partie de son espace d’adressage n’était pas utilisée.
Transition vers l’adressage sans classe (CIDR)
Pour résoudre ces problèmes, Internet est passé dans les années 1990 au routage interdomaine sans classe (CIDR). Le CIDR élimine les limites fixes des classes et permet aux blocs d’adresses d’être définis uniquement par la longueur du préfixe (par exemple, 192.0.2.0/23).
Les organisations peuvent donc recevoir des blocs d’adresses dont la taille est mieux adaptée à leurs besoins et que les fournisseurs de services Internet peuvent regrouper plusieurs petits réseaux en une seule entrée de routage grâce à l’agrégation de routes.
Le CIDR a également introduit une certaine souplesse dans la manière dont les blocs d’adresses pouvaient croître ou diminuer sans être liés aux anciennes limites A, B et C. En effet, le CIDR permet aux réseaux d’utiliser des longueurs de préfixes variables au lieu de classes fixes. Chaque bloc peut être défini avec n’importe quelle valeur de préfixe : par exemple, /22 pour environ 1 000 adresses ou /30 pour seulement quatre. Cette méthode, connue sous le nom de subdivision en sous-réseau à longueur variable, a permis aux organisations d’attribuer un espace d’adressage correspondant à leurs besoins réels au lieu de gaspiller les adresses inutilisées.
Aujourd’hui, la notation CIDR est utilisée universellement dans l’adressage IPv4 et IPv6. Même si la terminologie liée aux « classes » persiste dans certains contextes éducatifs ou hérités, les pratiques modernes de routage et d’attribution reposent entièrement sur l’adressage CIDR.
IPv6 et l’avenir de l’adressage
Le CIDR a prolongé la durée de vie de l’IPv4, mais comme on l’a déjà dit, son espace de 32 bits a quand même fini par s’épuiser. L’IPv6 a été créé pour résoudre ce problème et pour s’adapter à l’ampleur de l’Internet actuel. Il utilise des adresses de 128 bits, ce qui donne suffisamment de combinaisons pour que l’épuisement des adresses ne soit plus un problème.
L’adressage IPv6 a été conçu dès le départ autour d’un modèle hiérarchique sans classe. Les réseaux peuvent être divisés ou combinés de manière à répondre aux besoins de routage, qu’il s’agisse de fournisseurs mondiaux ou de petits systèmes locaux.
Il offre aussi des fonctionnalités dont IPv4 n’a jamais disposé, notamment la configuration automatique des adresses et le protocole IPsec (Internet Protocol Security) intégré. De plus, l’IPv6 utilise le multicast pour envoyer des messages réseau uniquement aux appareils qui en ont besoin, au lieu de les diffuser à tous les appareils du réseau. C’est plus rapide et cela réduit le trafic inutile.
FAQ : Questions fréquentes sur les classes d’adresses IP
Quelles sont les 5 classes d’adresses IP ?
Les adresses IPv4 étaient à l’origine divisées en 5 catégories : Les classes A, B, C, D et E. Les classes A à C prennent en charge des réseaux de différentes tailles, la classe D est utilisée pour le multicast et la classe E est réservée à la recherche et aux essais. Chaque classe détermine le nombre de réseaux et d’hôtes qui peuvent exister dans son rayon d’action.
Qu’est-ce qu’une adresse IP privée ?
Les adresses IP privées sont des blocs réservés à l’usage des réseaux locaux. Définies par la RFC 1918 (Request for Comments), elles comprennent 10.0.0.0/8, 172.16.0.0/12 et 192.168.0.0/16. Ces adresses ne sont pas accessibles sur l’Internet public. Les routeurs les traduisent en une adresse IP publique par le biais de la traduction d’adresses de réseau (NAT) lorsque les appareils se connectent à l’extérieur.
Comment le subnetting est-il lié aux classes d’adresses IP ?
La subdivision de réseau étend le modèle basé sur les classes en divisant un grand réseau IP en segments plus petits et structurés. Le réglage du masque de la subdivision en sous-réseau permet aux administrateurs de contrôler le nombre de sous-réseaux et de périphériques pris en charge par chaque segment. Cette approche modulaire évite le gaspillage d’adresses et améliore l’organisation et la sécurité du réseau.
Pourquoi les classes d’adresses IP sont-elles importantes ?
Le système de classes d’origine a façonné l’organisation des réseaux IPv4 et ouvert la voie au sous-réseau, à la traduction d’adresses de réseau (NAT) et à l’adressage privé. Bien qu’il ait été remplacé par l’adressage sans classe, la compréhension des classes permet d’expliquer la logique qui sous-tend la conception des réseaux actuels.
Les classes d’adresses IP sont-elles encore utilisées aujourd’hui ?
Ce n’est plus le cas aujourd’hui. Les réseaux actuels utilisent le Classless Inter-Domain Routing (CIDR), qui attribue les adresses en fonction de la longueur du préfixe plutôt que de classes fixes.
Prenez les premières mesures pour assurer votre sécurité en ligne. Essayez ExpressVPN sans courir le moindre risque.
Obtenez ExpressVPN